development
Cabel Sasser's talk at C4
Sunday, 30 March 2008
I just finished watching Cabel Sasser, from Panic Software, talking about the design and development of Coda, their website development application, at the C4 Macintosh Developers' Conference. He's a great speaker: very dynamic, and funny, and his mannerisms bear an eerie resemblance to those of someone who used to work with me. His Keynote slides were good too; I must remember to include a vomiting kid in my next presentation!
Here's the video from the talk; highly recommended.
Here's the video from the talk; highly recommended.
Lambda Functions and Closures officially in C++0x
Saturday, 29 March 2008
Herb Sutter just posted about the most recent ISO C++ Standards Meeting. The most exciting news is that lambda functions and closures have been officially voted into C++0x! This is really going to make taking advantage of the Standard Algorithms much more straightforward.
Here's a little taste from Herb's post:
Yes, you can already achieve the same thing today, with a standard binary predicate and a helper, thusly:
find_if(w.begin(), w.end(), bind2nd(greater<int>(), 100));
but it isn't nearly as easy on the eye, is it?
Lambda functions will also make it a lot easier in situations where now you'd be forced to use a custom predicate; previously you'd have to: create a functor; remember to make it inherit from std::unary_function or std::binary_function for completeness; stick it in an anonymous namespace (optional but recommended; and finally, use it in your invocation of one of the standard algorithms. That works, but if you're coding a for_each, because you're trying to be good and not write a loop on an STL container by hand, then having the interesting part of the loop in a functor makes the code much harder to follow: instead of it being right there in the loop, it has to be somewhere else, breaking up the flow of the logic in the poor reviewer's head.
Here's a little taste from Herb's post:
In C++0x, you can just write:
// Calling find_if using a lambda, in C++0x:
find_if( w.begin(), w.end(),
[]( const Widget& w ) -> bool { w.Weight() > 100; } );
Yes, you can already achieve the same thing today, with a standard binary predicate and a helper, thusly:
find_if(w.begin(), w.end(), bind2nd(greater<int>(), 100));
but it isn't nearly as easy on the eye, is it?
Lambda functions will also make it a lot easier in situations where now you'd be forced to use a custom predicate; previously you'd have to: create a functor; remember to make it inherit from std::unary_function or std::binary_function for completeness; stick it in an anonymous namespace (optional but recommended; and finally, use it in your invocation of one of the standard algorithms. That works, but if you're coding a for_each, because you're trying to be good and not write a loop on an STL container by hand, then having the interesting part of the loop in a functor makes the code much harder to follow: instead of it being right there in the loop, it has to be somewhere else, breaking up the flow of the logic in the poor reviewer's head.
SQLite
Sunday, 23 March 2008
We've incorporated SQLite* into a project at work recently. If you haven't come across it before, SQLite is "a software library that implements a self-contained, serverless, zero-configuration, transactional SQL database engine". Pretty good for a library that weighs in at less than 250KB, huh? It's also trivial to embed, with its amalgamated version (where much of the precompilation is done already) consisting of just one C source file and one header file. There are also wrappers for SQLite's C API available for lots of languages, from .html to Tcl/Tk; there's even an ODBC driver for it if you're into that sort of thing.
You can use a command line tool to interact with the database, or more commonly, you can integrate the library into your application directly. It's very full featured, with only a few SQL features missing (right outer joins, updatable views, foreign key enforcement, and a couple of other things), so you can perform some pretty powerful operations on your data right out of the box.
Transactions use a journal file, so if power is lost during an update, SQLite will automatically rollback the incomplete transaction when power is resumed. This robustness, couple with its size, makes SQLite very popular with embedded device and cell phone manufacturers. It's used in many cell phones, and it is embedded into Apple Mail and many other common applications, including Firefox.
The implementation of SQLite is pretty interesting, in that it compiles statements to byte code for its own virtual machine when you prepare them. The command line tool even has an EXPLAIN command that lets you see the byte code that a statement will generate, so you can see how it will run and potentially do some optimization. The code is well written and well documented. The code base has a 60/40 split between test code and source code and its regression tests have 98% code coverage. I wish I could say that about all of the projects that I've worked on over the years.
Here's some resources if you would like to find out more about SQLite:
- Leo Laporte and Randal Schwartz talked to SQLite's author D. Richard Hipp recently on episode 26 of the FLOSS podcast.
- There is an excellent book on SQLite by Mike Owens. It covers all aspects of SQLite, from its inception to writing extensions for it. There's also a couple of chapters that provide a nice introduction to relational database theory, and SQL. The only bad thing I can say about this book is that its index is next to useless.
on SQLite by Mike Owens. It covers all aspects of SQLite, from its inception to writing extensions for it. There's also a couple of chapters that provide a nice introduction to relational database theory, and SQL. The only bad thing I can say about this book is that its index is next to useless.
- There's also a nice video of D. Richard Hipp presenting "An Introduction to SQLite" at Google in May of 2006:
*Pronounced ess-que-ell-lite according to its author (and he should know).
You can use a command line tool to interact with the database, or more commonly, you can integrate the library into your application directly. It's very full featured, with only a few SQL features missing (right outer joins, updatable views, foreign key enforcement, and a couple of other things), so you can perform some pretty powerful operations on your data right out of the box.
Transactions use a journal file, so if power is lost during an update, SQLite will automatically rollback the incomplete transaction when power is resumed. This robustness, couple with its size, makes SQLite very popular with embedded device and cell phone manufacturers. It's used in many cell phones, and it is embedded into Apple Mail and many other common applications, including Firefox.
The implementation of SQLite is pretty interesting, in that it compiles statements to byte code for its own virtual machine when you prepare them. The command line tool even has an EXPLAIN command that lets you see the byte code that a statement will generate, so you can see how it will run and potentially do some optimization. The code is well written and well documented. The code base has a 60/40 split between test code and source code and its regression tests have 98% code coverage. I wish I could say that about all of the projects that I've worked on over the years.
Here's some resources if you would like to find out more about SQLite:
- Leo Laporte and Randal Schwartz talked to SQLite's author D. Richard Hipp recently on episode 26 of the FLOSS podcast.
- There is an excellent book
- There's also a nice video of D. Richard Hipp presenting "An Introduction to SQLite" at Google in May of 2006:
*Pronounced ess-que-ell-lite according to its author (and he should know).
The Way of the Brew Peg
Wednesday, 19 March 2008
I've been a software engineer for quite a while now. How long, you ask? Let's just say that the waterfall model was state of the art when I was studying* for my CS degree. Actually, despite it being the title on my business card, I've always been reluctant to refer to myself as an engineer; writing code has always seemed to me more of a creative process, than one of precision as would befit the title "engineer". Code is constrained more by the experience and imagination of its creator, than by such practical considerations as capacitance and resistance that are the realm of an electrical engineer, to whom the title of engineer seems far more apropos.
But that isn't to say that the work days of we code monkeys are entirely devoid of process. I think it is terribly important to learn from the mistakes we've made in the past. We've learned that customers could not reasonably be expected to completely understand up front what it is they wanted a computer program to do; and so, the rather rigid waterfall model fell by the way side. In its stead we now see predominately iterative models, with Agile seemingly leading the charge these days. This is all good progress, barring the odd self-indulgent wallowing in buzzwords that we've seen along the way. Still, I'm not much of one for blind faith when it comes to software development models or design practices; I don't particularly try and follow any given formal method of decomposition during design, or care whether a particular refactoring I just did has a cool name. So what do I do?
I follow The Way of The Brew Peg:

So what the heck is The Way of the Brew Peg? Well, at work we have a large coffee pot. It is filled often, as you might imagine, but there's a problem: it's very hard to tell, without stooping down and peering between the filter cup and the pot, whether the coffee is still brewing. Hence, there have been many cases of still-pouring coffee making its way onto the counter and floor as one poor caffeine-seeking soul pulls the pot out prematurely. Sure, an upgrade to a fancier coffee pot might have done the trick: had a glaring brew-indicator lamp, or a locking mechanism of some form. And we even have one of the most imposing looking coffee-in-a-teabag-thingies too.
But you know what works great? A plain wooden clothes peg clipped to the handle of the pot. When your sleep-addled brain tells your hand to pick up the pot, your hand spots the impediment in its path and quickly relays caution back to the brain. Those two small pieces of wood held together with a spring have saved you from embarrassment, a potential scalding and some floor cleaning.
The brew peg keeps me grounded. So while I consider the possibility of reuse when defining objects and interfaces, the brew peg stops me from taking that consideration too far, so that the intended purpose - right here, right now - of that object or interface is not compromised by some potentially nonexistent future need. The brew peg is the physical embodiment of practical simplicity; and, it's comforting to have an actual physical mnemonic in my design process to balance the otherwise overwhelming abstractness of it all.**
So when you're writing that next design document, or defining that API, remember the brew peg. It may not have the pizzazz of a YAGNI or a KISS, but will they keep you from burning your hand?
* where by studying, I mean: playing Super Nintendo while watching Neighbours and listening to "Fools Gold 9:53" by The Stone Roses (played at 33⅓ RPM even though it was recorded at 45 RPM)
** which is also why I like woodworking, as awful as I am at it
But that isn't to say that the work days of we code monkeys are entirely devoid of process. I think it is terribly important to learn from the mistakes we've made in the past. We've learned that customers could not reasonably be expected to completely understand up front what it is they wanted a computer program to do; and so, the rather rigid waterfall model fell by the way side. In its stead we now see predominately iterative models, with Agile seemingly leading the charge these days. This is all good progress, barring the odd self-indulgent wallowing in buzzwords that we've seen along the way. Still, I'm not much of one for blind faith when it comes to software development models or design practices; I don't particularly try and follow any given formal method of decomposition during design, or care whether a particular refactoring I just did has a cool name. So what do I do?
I follow The Way of The Brew Peg:
So what the heck is The Way of the Brew Peg? Well, at work we have a large coffee pot. It is filled often, as you might imagine, but there's a problem: it's very hard to tell, without stooping down and peering between the filter cup and the pot, whether the coffee is still brewing. Hence, there have been many cases of still-pouring coffee making its way onto the counter and floor as one poor caffeine-seeking soul pulls the pot out prematurely. Sure, an upgrade to a fancier coffee pot might have done the trick: had a glaring brew-indicator lamp, or a locking mechanism of some form. And we even have one of the most imposing looking coffee-in-a-teabag-thingies too.
But you know what works great? A plain wooden clothes peg clipped to the handle of the pot. When your sleep-addled brain tells your hand to pick up the pot, your hand spots the impediment in its path and quickly relays caution back to the brain. Those two small pieces of wood held together with a spring have saved you from embarrassment, a potential scalding and some floor cleaning.
The brew peg keeps me grounded. So while I consider the possibility of reuse when defining objects and interfaces, the brew peg stops me from taking that consideration too far, so that the intended purpose - right here, right now - of that object or interface is not compromised by some potentially nonexistent future need. The brew peg is the physical embodiment of practical simplicity; and, it's comforting to have an actual physical mnemonic in my design process to balance the otherwise overwhelming abstractness of it all.**
So when you're writing that next design document, or defining that API, remember the brew peg. It may not have the pizzazz of a YAGNI or a KISS, but will they keep you from burning your hand?
* where by studying, I mean: playing Super Nintendo while watching Neighbours and listening to "Fools Gold 9:53" by The Stone Roses (played at 33⅓ RPM even though it was recorded at 45 RPM)
** which is also why I like woodworking, as awful as I am at it
You don't know the power of the darkside MacBook
Sunday, 24 February 2008
I was catching up on some work tonight. I had a Visual Studio 2005 application running on an XP machine, connected via TCP/IP to a Java server application running on a Fedora Core 8 machine. During compilation, and commits to source control, I was going through my news feeds in NetNewsWire on my MacBook.
No big deal, right? Well, the interesting thing is that only the MacBook was a real machine: the XP and Fedora machines were actually virtual, and running on the MacBook courtesy of VMWare Fusion. It hit me just how much computing power we have at our disposal these days: a 15-month old consumer-grade laptop running 2 virtual machines plus its own applications, all simultaneously and without any perceptible slowdown: this is not even a MacBook Pro!
Here's what my Spaces-plus-Expose view shows me (Spaces is Leopard's multiple-desktop implementation, and Expose is OS X's way of showing you all the active windows on your desktop, so you can pick one to switch to; in true Apple-cool fashion, if you bring up the Spaces view and then ask for the Expose view it shows you the Expose view for each one of your desktops simultaneously):
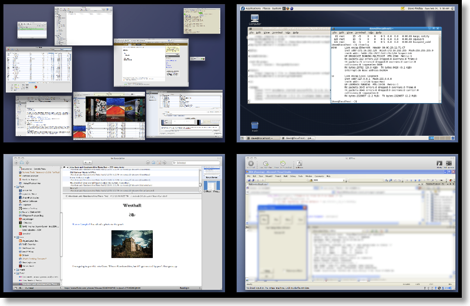
In the top-left we have space number 1, where: I have started to write this post in RapidWeaver; iTunes is running (that's Californication from Red Hot Chili Peppers at the front, if you were wondering); Transmission is seeding the Fedora Core 8 DVD ISO; OmniFocus, iChat, Terminal, Mail and Safari are all doing their thing; and Activity Monitor is letting me know how this is all going. It's not shown, (eggs, chickens and what not) but I had Pixelmator going as well, long enough to blur a couple parts of the screenshot to protect the innocent.
In the top-right, the Fedora 8 VMWare Fusion virtual machine is running a Java server application and its database backend.
In the bottom-left, NetNewsWire is keeping me up-to-date.
Finally, in the bottom-right, the XP VMWare Fusion virtual machine is running Visual Studio 2005 debugging an MFC application; by the way, I don't know MFC.
Here's a close up of Activity Monitor, with the memory tab active, sorted by descending order of use of real memory:
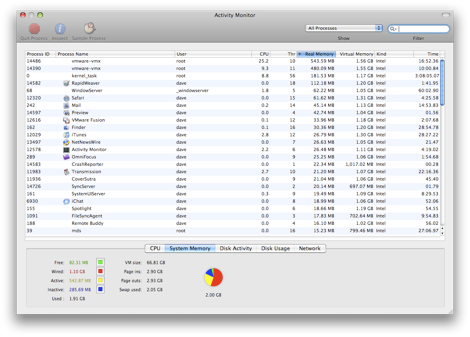
The big hitters, unsurprisingly, are the two virtual machines, weighing in at around 500MB each. They were both configured with 512MB of RAM, so that makes sense. Next we have the kernel, close followed by RapidWeaver (the application that I use to write this). From there you're down in the weeds of measly 60MB chunks of RAM here and 40MB chunks of RAM there. From the stats at the bottom, you can see that there's 369MB (sum of free and inactive) of RAM free (see this Apple article for an explanation of the different categories of memory).
And just think, if you buy a MacBook now you can fit 4GB in it and the integrated graphics are faster than mine. How many VMs can you run?
No big deal, right? Well, the interesting thing is that only the MacBook was a real machine: the XP and Fedora machines were actually virtual, and running on the MacBook courtesy of VMWare Fusion. It hit me just how much computing power we have at our disposal these days: a 15-month old consumer-grade laptop running 2 virtual machines plus its own applications, all simultaneously and without any perceptible slowdown: this is not even a MacBook Pro!
Here's what my Spaces-plus-Expose view shows me (Spaces is Leopard's multiple-desktop implementation, and Expose is OS X's way of showing you all the active windows on your desktop, so you can pick one to switch to; in true Apple-cool fashion, if you bring up the Spaces view and then ask for the Expose view it shows you the Expose view for each one of your desktops simultaneously):
In the top-left we have space number 1, where: I have started to write this post in RapidWeaver; iTunes is running (that's Californication from Red Hot Chili Peppers at the front, if you were wondering); Transmission is seeding the Fedora Core 8 DVD ISO; OmniFocus, iChat, Terminal, Mail and Safari are all doing their thing; and Activity Monitor is letting me know how this is all going. It's not shown, (eggs, chickens and what not) but I had Pixelmator going as well, long enough to blur a couple parts of the screenshot to protect the innocent.
In the top-right, the Fedora 8 VMWare Fusion virtual machine is running a Java server application and its database backend.
In the bottom-left, NetNewsWire is keeping me up-to-date.
Finally, in the bottom-right, the XP VMWare Fusion virtual machine is running Visual Studio 2005 debugging an MFC application; by the way, I don't know MFC.
Here's a close up of Activity Monitor, with the memory tab active, sorted by descending order of use of real memory:
The big hitters, unsurprisingly, are the two virtual machines, weighing in at around 500MB each. They were both configured with 512MB of RAM, so that makes sense. Next we have the kernel, close followed by RapidWeaver (the application that I use to write this). From there you're down in the weeds of measly 60MB chunks of RAM here and 40MB chunks of RAM there. From the stats at the bottom, you can see that there's 369MB (sum of free and inactive) of RAM free (see this Apple article for an explanation of the different categories of memory).
And just think, if you buy a MacBook now you can fit 4GB in it and the integrated graphics are faster than mine. How many VMs can you run?
MEDC 2006
Saturday, 13 May 2006
I just got back from Microsoft's Mobile and Embedded DevCon. It was hosted at The Venetian in Las Vegas. On Tuesday night they had Tao, this nightclub in the hotel, reserved exclusively for MEDC; it must have been the largest nerd conglomeration in a nightclub ever! We entered the SumoRobot challenge, where we had to program the AI in a Parallax SumoRobot modified to use the new .NET Micro Framework. I lost one of the IR sensors on the way into the ring and the poor robot was never the same after that.
Oh well. So CE6 looks like it will be very interesting. We got betas of it and the big news is they've ditched the 32/32 limit of past CEs (up to 32 processes each with a 32Mb 'slot' of virtual address space); in CE6 each process gets its own 2Gb of virtual address space and up to 32k processes can be running simultaneously. Addressing of physical RAM is still limited to 512Mb, but DLLs now go in a shared 512Mb region of virtual address space, instead of eating from the 32Mb ceiling on down like before. That should mean worrying about DLL crunch when developing applications for PPC/WM is a thing of the past, at least for a little while.
On the whole I was glad I went. Most of the sessions were enlightening to one degree or another, although there were a couple of nightmares. One session included the pearl of wisdom "the emulator is good for emulating things". Boy, I'm glad my manager was at that one instead of me.
Oh well. So CE6 looks like it will be very interesting. We got betas of it and the big news is they've ditched the 32/32 limit of past CEs (up to 32 processes each with a 32Mb 'slot' of virtual address space); in CE6 each process gets its own 2Gb of virtual address space and up to 32k processes can be running simultaneously. Addressing of physical RAM is still limited to 512Mb, but DLLs now go in a shared 512Mb region of virtual address space, instead of eating from the 32Mb ceiling on down like before. That should mean worrying about DLL crunch when developing applications for PPC/WM is a thing of the past, at least for a little while.
On the whole I was glad I went. Most of the sessions were enlightening to one degree or another, although there were a couple of nightmares. One session included the pearl of wisdom "the emulator is good for emulating things". Boy, I'm glad my manager was at that one instead of me.